
In the past, recommender systems have been riddled with complex features and considered a luxury for most companies to have. Today we’re seeing these systems increasingly become a necessity used for personalization in many sectors across all industries such as healthcare, nutrition, entertainment, marketing, and more. Recommender systems aim to predict users’ interests based on pre-existing data and recommend product items that are most likely to align with their interests or the most effective solution to their problem. In this article, we explore the evolution of emerging recommender systems that use a multi-armed bandit approach, which incorporates a variety of algorithms that adaptively respond to new user data.
Recommendation engines are comprised of separate machine learning (ML) algorithms that bridge at least two knowledge domains. This allows for more effective matching across domains and connecting solutions to needs. In short, they help discover connections that are difficult to find. Strategies employed by 1st generation recommender systems typically require viewer-specific data in order to perform well, which ultimately lessens the effectiveness of these systems until such data can be gathered. This is commonly referred to as the “cold start problem.” Implementing multi-armed bandit algorithms is one way to confront these challenges.
Reinforcement Learning for Recommender System Optimization
Current recommendation engines pick an approach to connection by selecting the best model (Global trends, Content-Based, Collaborative Filtering) and applying it across a single connection point. If that changes over time, the engine does not adapt accordingly. Reinforcement learning (RML) is a branch of machine learning that takes the approach of learning from experience and feedback. In RML, models self-adjust their individual actions to optimize a collective outcome. These models operate more autonomously than pre-pandemic models and fully embrace early failures in favor of more valuable long-term gains through repeated environment exploration and self-learning.
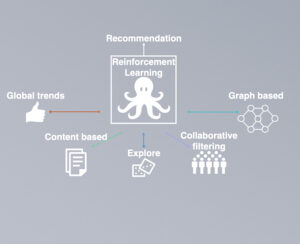
Beowulf, Valkyrie’s Recommendation Engine, leverages a reinforcement learning approach. Beowulf adaptively and continuously evaluates the best algorithm options, among many potentials, for determining the most effective and valuable recommendation. Recommender systems using the multi-arm bandit approach, are more effective than the systems that work individually. The process provides the opportunity for a collection of combined systems to observe and learn about the effectiveness of the combined algorithms, and progressively improve the group configuration.
To learn more about Valkyrie’s recommender system, download our one-page executive summary here:

